https://help.miro.com/hc/en-us/articles/4409706795410-Clustering-BETA-
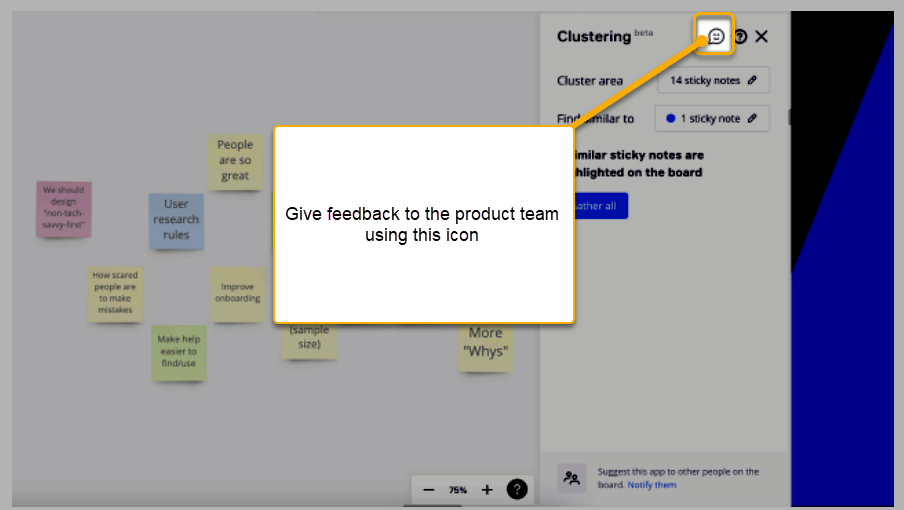
Definitely need to improve this so it can disambiguate real user research interview data (JTBD data example attached). The idea is to improve the algo, as I am not able to affinitize unstructured data very well. The tool, as of now, is ok at separating simple and short unclassified data. What I am asking for is very hard, but very worth it. No one has actually built a good qualitative data tool to structure unstructured interview data.